
 LinkBack URL
LinkBack URL About LinkBacks
About LinkBacks
Big Data Processing using Apache Spark
MP4 | Video: AVC 1280x720 | Audio: AAC 44KHz 2ch | Duration: 1.5 Hours | 278 MB
Genre: eLearning | Language: English
Every year we have a big increment of data that we need to store and analyze. When we want to aggregate all data about our users and analyze that data to find insights from it, terabytes of data undergo processing. To be able to process such amounts of data, we need to use a technology that can distribute multiple computations and make them more efficient. Apache Spark is a technology that allows us to process big data leading to faster and scalable processing.
In this course, we will learn how to leverage Apache Spark to be able to process big data quickly. We will cover the basics of Spark API and its architecture in detail. In the second section of the course, we will learn about Data Mining and Data Cleaning, wherein we will look at the Input Data Structure and how Input data is loaded In the third section we will be writing actual jobs that analyze data. By the end of the course, you will have sound understanding of the Spark framework which will help you in writing the code understand the processing of big data.
Download link:
uploadgig_com:
[Misafirler Kayıt Olmadan Link Göremezler Lütfen Kayıt İçin Tıklayın ! ]
uploaded_net:
[Misafirler Kayıt Olmadan Link Göremezler Lütfen Kayıt İçin Tıklayın ! ]Links are Interchangeable - No Password - Single Extraction

1 sonuçtan 1 ile 1 arası
-
03.06.2017 #1Üye


")
- Üyelik tarihi
- 20.08.2016
- Mesajlar
- 147.735
- Konular
- 0
- Bölümü
- Bilgisayar
- Cinsiyet
- Kadın
- Tecrübe Puanı
- 157
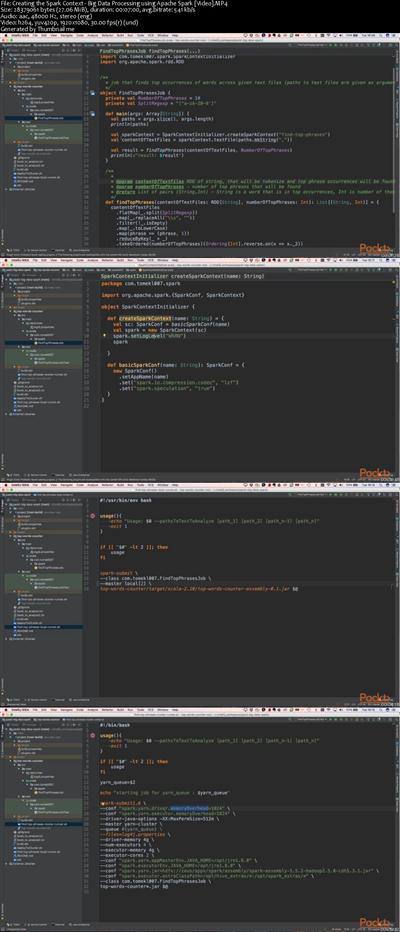
Big Data Processing using Apache Spark.


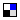


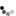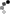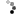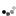
 Alıntı
AlıntıKonu Bilgileri
Users Browsing this Thread
Şu an 1 kullanıcı var. (0 üye ve 1 konuk)

Konuyu Favori Sayfanıza Ekleyin